Edge Computing en visión artificial mediante Deep Learning ¿Qué es?
Tiempo de lectura: 5 minutosEn esta nueva era donde la inteligencia artificial es la tecnología que se prevé tenga mayor influencia en nuestra sociedad, es importante dado el gran abanico de casos de usos y la gran competencia existente adaptar cada solución según las necesidades requeridas.
¿Qué es el Edge Computing? Las aplicaciones de visión artificial basadas en Deep Learning han sido una revolución en el mundo de la visión por computador y ofrecen unos resultados impensables hace poco más de 10 años. Los avances en este campo han permitido solventar aplicaciones de clasificación y segmentación de imágenes, generación de datos sintéticos, transferencia de estilos, generación de imágenes a partir de texto, super resolución o detección de objetos, entre muchas otras.

El avance del software ha podido llegar en gran parte gracias a la aparición del big data, que permite la creación de grandes datasets con imágenes anotadas según la tarea a resolver para el entrenamiento de nuestros modelos de IA, y al avance en el hardware, con la aparición de unidades de computación paralela como las gpus, que permiten poder entrenar y ejecutar modelos con millones de parámetros en tiempos directamente proporcionales al hardware asociado. Delante de un proyecto de visión artificial basado en tecnología Deep Learning, si nos fijamos en el pipeline, podemos establecer dos fases que se conocen como etapa de entrenamiento del modelo y etapa de implementación o inferencia. Conoce el pipeline en modelos de Deep Learning para visión artificial para saber que es Edge Computing.
Pipeline en modelos de Deep Learning para visión artificial
En la etapa de entreno, vamos a alimentar a nuestro modelo con un dataset dividido en imágenes de entreno y de validación, que nos permita enseñarle a solventar una o varias tareas. Introduciendo grupos de imágenes como entrada de nuestra red neuronal podemos calcular el error con diferentes funciones de perdida en las predicciones y volver hacia atrás mediante una técnica conocida como backpropagation que irá corrigiendo poco a poco aquellas operaciones que han influenciado a confundir a nuestro modelo en el resultado generado. Iterando esta secuencia, podremos evaluar gracias a diferentes métricas como nuestro modelo va aprendiendo a solventar el reto al que se está enfrentando. Una vez tenemos el resultado esperado, pasamos a la fase de implementación o inferencia, donde nuestro modelo se va a enfrentar a datos que no ha visto previamente y que debería ser capaz de predecir correctamente.
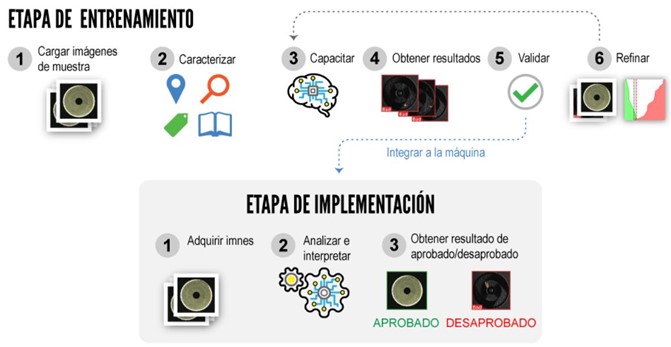
Figura 2. Pipeline para un modelo Deep Learning en visión artificial: Cognex (2022)
Etapa de entrenamiento
En la fase de entreno, es importante poder contar con un hardware potente ya sea a nivel local, en red o en la nube que nos permita entrenar nuestros modelos de la forma más rápida y efectiva posible. El uso de las gpus, diseñadas inicialmente para el computo en paralelo de gráficos, irrumpió en el mundo del Deep Learning de forma generalizada a principios del 2010, gracias a los avances en el hardware y la adaptación de CUDA, que es una librería de nvidia escrita en c/c++ para la gestión y sincronización de datos entre cpu y gpu y la ejecución de operaciones entre matrices de forma paralela, que son la base del cómputo en Deep Learning. El éxito de las gpu es que estos sistemas son más efectivos en el procesamiento masivo en paralelo para cálculos repetitivos e idénticos, en comparación con las CPU.
En la actualidad tenemos muchas opciones de acceso a hardware para la fase de entrenamiento de nuestros modelos de Deep Learning y dependerá de los requerimientos de nuestra aplicación, el presupuesto disponible o la escalabilidad del proyecto la decisión de que opción utilizar o en que solución invertir. El número de parámetros del modelo, el batch size escogido, el tamaño de la imagen que queremos procesar, entre otros factores determinaran los recursos mínimos que necesitaremos tales como la memoria ram, la cpu, el disco duro, la memoria o el número de núcleos de la gpu, el consumo eléctrico, entre otros.

Figura 3. Nvidia gpus para Deep Learning: Google (2022)
Etapa de implementación
En esta fase debemos tener en cuenta nuevamente los requerimientos de nuestra aplicación para poder decidir que hardware o plataforma de inferencia vamos a utilizar. El tiempo de respuesta requerido para nuestro sistema es un factor muy importante, ya que algunas aplicaciones exigen una respuesta rápida, como sería el caso de un sistema de seguridad para evitar hurtos en una tienda o conducción autónoma, mientras que en otras el resultado puede entregarse con un cierto retardo, como por ejemplo en el caso donde un usuario hace una foto de una planta con su móvil, este la sube a un servidor externo que ejecuta el modelo y le envía el resultado de que planta es nuevamente al dispositivo.
Se conoce como Edge Computing a realizar la inferencia y por lo tanto la ejecución del modelo de Deep Learning lo más cerca posible de la fuente de adquisición de datos. Esto permite agilizar el procesamiento pudiendo trabajar con mayor rapidez y eficacia, ya que reduce la latencia, aumenta la seguridad de nuestros datos y mejorar la experiencia del usuario y el rendimiento general.
En el mundo de la visión artificial disponemos de muchas opciones de hardware para Edge computing, desde potentes máquinas de procesado con gpus instaladas a pie de línea de producción que nos permiten ejecutar modelos muy potentes para detección de anomalías a grandes cadencias, hasta sistemas embebidos de menor capacidad de procesamiento como por ejemplo nuestro smartphone, sistemas arm o microcontroladores.
Dependiendo del hardware y de los requerimientos de nuestra aplicación, nuestro modelo podrá ser mayor o menor, es decir que tendrá más o menos parámetros para calcular. Para ello se pueden utilizar distintas estrategias como el uso de diferentes arquitecturas o backbones más o menos densos capaces de solventar el mismo problema sin afectar a la eficiencia, se pueden emplear técnicas de prunnning que reducen redundancia en parámetros de nuestra red, o la cuantización que permite reducir la cantidad de bits necesarios para almacenar los datos de nuestro modelo y acelerar el coste de las operaciones, incluso la optimización de gráficos que incluyen algunas librerías que permiten optimizar el diseño y simplificar o unificar nodos de nuestra arquitectura, entre otros.

Conclusión
En esta nueva era donde la inteligencia artificial es la tecnología que se prevé tenga mayor influencia en nuestra sociedad, es importante dado el gran abanico de casos de usos y la gran competencia existente adaptar cada solución según las necesidades requeridas. Por este motivo, se están haciendo grandes esfuerzos por parte de muchas empresas y de la comunidad científica en la optimización de hardware y software que permitan que el Edge Computing sea cada vez más eficiente sin perjudicar a la precisión obtenida por nuestro modelo en la fase de entrenamiento. No obstante, dado los avances en velocidad de tecnologías en telecomunicaciones como el 5G, la necesidad de procesar los datos cerca de la fuente(Edge Computing), podría verse modificada en los años venideros si las tasas de transferencia y el ancho de banda son suficientes para poder dar respuestas los suficientemente rápidas para que la aplicación no se vea alterada.
Escrito por Sergio Redondo Cabanillas, R&D Manager en Grupo Bcnvision.
¿Quieres seguir leyendo blogs sobre visión artificial? haz clic aquí
Conocer soluciones reales de visión
¿Tienes un proyecto y necesitas realizar alguna consulta sobre Edge Computing o Deep Learning?
Contacta con Bcnvision.