Edge Learning en vision industrielle. Qu’est-ce que c’est ?
Qu’est-ce que le Edge Learning ? Les applications de vision industrielle basées sur le Deep Learning ont constitué une révolution dans le monde de la vision par ordinateur et offrent des résultats qui étaient impensables il y a un peu plus de 10 ans. Les progrès réalisés dans ce domaine ont permis de résoudre des applications de classification et de segmentation d’images, de génération de données synthétiques, de transfert de style, de génération d’images à partir de textes, de super résolution ou de détection d’objets, parmi beaucoup d’autres.

Les progrès logiciels ont été possibles en grande partie grâce à l’apparition du big data, qui permet de créer de grands ensembles de données avec des images annotées en fonction de la tâche à résoudre pour l’entraînement de nos modèles d’IA, et aux progrès matériels, avec l’apparition d’unités de calcul parallèles comme les gpus, qui permettent d’entraîner des modèles avec des millions de paramètres et de les exécuter dans des temps directement proportionnels au matériel associé. Face à un projet de vision industrielle basé sur la technologie Deep Learning, si nous examinons le pipeline, nous pouvons établir deux phases connues sous le nom d’étape de formation du modèle et d’étape d’implémentation ou d’inférence. Découvrez le pipeline des modèles Deep Learning pour la vision industrielle afin de savoir ce qu’est l’Edge Computing.
Pipeline sur les modèles de Deep Learning pour la vision industrielle
Dans la phase d’entraînement, nous allons alimenter notre modèle avec un jeu de données divisé en images d’entraînement et de validation, ce qui nous permettra de lui apprendre à résoudre une ou plusieurs tâches. En introduisant des groupes d’images en entrée de notre réseau neuronal, nous pouvons calculer l’erreur avec différentes fonctions de perte dans les prédictions et revenir en arrière en utilisant une technique connue sous le nom de rétropropagation, qui corrigera progressivement les opérations qui ont influencé notre modèle pour brouiller le résultat généré. En itérant cette séquence, nous pourrons évaluer, grâce à différentes métriques, comment notre modèle apprend à résoudre le défi auquel il est confronté. Une fois que nous avons le résultat attendu, nous passons à la phase d’implémentation ou d’inférence, où notre modèle va être confronté à des données qu’il n’a pas vues auparavant et qu’il doit pouvoir prédire correctement.
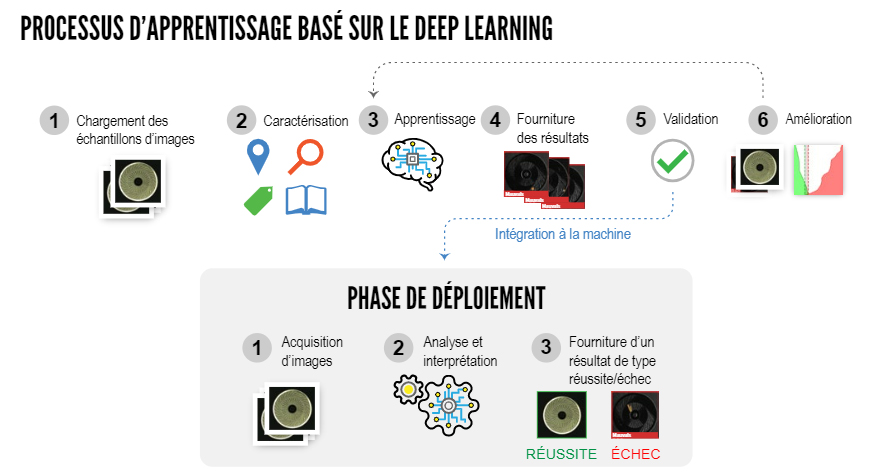
Phase de formation
Dans la phase de formation, il est important de pouvoir compter sur un matériel puissant, qu’il soit local, en réseau ou dans le nuage, pour former nos modèles aussi rapidement et efficacement que possible. L’utilisation des gpus, initialement conçus pour le calcul parallèle de graphiques, a fait irruption dans le monde du Deep Learning de manière généralisée au début de l’année 2010, grâce aux progrès du matériel et à l’adaptation de CUDA, qui est une bibliothèque de Nvidia écrite en c/c++ pour la gestion et la synchronisation des données entre cpu et gpu et l’exécution d’opérations entre matrices en parallèle, qui sont la base du calcul dans le Deep Learning. Le succès des gpu réside dans le fait que ces systèmes sont plus efficaces dans le traitement massivement parallèle pour les calculs répétitifs et identiques, par rapport aux CPU.
Actuellement, nous avons de nombreuses options pour accéder au matériel pour la phase de formation de nos modèles Deep Learning et cela dépendra des exigences de notre application, du budget disponible ou de l’évolutivité du projet pour décider de l’option à utiliser ou de la solution dans laquelle investir. Le nombre de paramètres du modèle, la taille du lot choisi, la taille de l’image que nous voulons traiter, entre autres facteurs, détermineront les ressources minimales dont nous avons besoin telles que la mémoire RAM, le processeur, le disque dur, la mémoire ou le nombre de cœurs du processeur graphique, la consommation d’énergie, entre autres.

Phase de mise en œuvre
Dans cette phase, nous devons à nouveau tenir compte des exigences de notre application afin de décider du matériel ou de la plate-forme d’inférence à utiliser. Le temps de réponse requis pour notre système est un facteur très important, car certaines applications exigent une réponse rapide, comme dans le cas d’un système de sécurité pour prévenir le vol à l’étalage ou la conduite autonome, tandis que dans d’autres cas, le résultat peut être fourni avec un certain retard, comme par exemple dans le cas où un utilisateur prend une photo d’une plante avec son téléphone portable, la télécharge vers un serveur externe qui exécute le modèle et renvoie le résultat de la plante à l’appareil.
L’Edge Computing est connu pour effectuer l’inférence et donc l’exécution du modèle de Deep Learning au plus près de la source d’acquisition des données. Cela nous permet d’accélérer le traitement et de travailler plus rapidement et plus efficacement, car cela réduit la latence, augmente la sécurité de nos données et améliore l’expérience utilisateur et les performances globales.
Dans le monde de la vision industrielle, nous disposons de nombreuses options matérielles pour l’Edge Computing, depuis les puissantes machines de traitement avec gpus installées sur la chaîne de production qui nous permettent d’exécuter des modèles très puissants pour la détection d’anomalies à des taux élevés, jusqu’aux systèmes embarqués avec une capacité de traitement plus faible comme notre smartphone, les systèmes de bras ou les microcontrôleurs.
Selon le matériel et les exigences de notre application, notre modèle peut être plus ou moins grand, c’est-à-dire qu’il aura plus ou moins de paramètres à calculer. Différentes stratégies peuvent être utilisées pour y parvenir, comme l’utilisation de différentes architectures ou dorsales plus ou moins denses, capables de résoudre le même problème sans affecter l’efficacité, des techniques d’élagage peuvent être utilisées pour réduire la redondance dans les paramètres de notre réseau, ou la quantification, qui réduit le nombre de bits nécessaires pour stocker les données de notre modèle et accélère le coût des opérations, et même l’optimisation des graphes, qui comprend certaines bibliothèques qui optimisent la conception et simplifient ou unifient les nœuds de notre architecture, entre autres.

Conclusion
Dans cette nouvelle ère où l’intelligence artificielle est la technologie qui devrait avoir la plus grande influence sur notre société, il est important, étant donné le large éventail de cas d’utilisation et la grande concurrence existante, d’adapter chaque solution en fonction des besoins requis. C’est pourquoi de nombreuses entreprises et la communauté scientifique déploient de gros efforts pour optimiser le matériel et les logiciels afin de rendre l’Edge Computing de plus en plus efficace sans compromettre la précision obtenue par notre modèle dans la phase d’apprentissage. Toutefois, compte tenu des progrès en matière de vitesse des technologies de télécommunications telles que la 5G, la nécessité de traiter les données à proximité de la source (Edge Computing) pourrait être modifiée dans les années à venir si les taux de transfert et la bande passante sont suffisants pour pouvoir fournir des réponses suffisamment rapides pour que l’application ne soit pas altérée.
Écrit par Sergio Redondo Cabanillas, Responsable R&D chez Bcnvision Group.
Vous voulez lire d’autres articles techniques ?
Vous avez un projet et vous avez besoin de poser une question?
Contact avec Bcnvision




